Crawler Web
Présentation du projet
Explication du projet
Le projet consiste à développer un crawler web, un programme capable de parcourir automatiquement les pages d’un site web en suivant les liens internes. L'objectif est de récupérer toutes les URLs d’un site sans visiter deux fois la même page, en respectant une logique d’exploration efficace.
Ce projet est né de ma curiosité pour le fonctionnement des moteurs de recherche. Je voulais comprendre comment une machine pouvait explorer un site de manière automatique, et surtout comment structurer cette exploration efficacement.
Objectifs
- Analyser un problème complexe et le décomposer en sous-tâches algorithmiques.
- Implémenter deux versions différentes : une récursive et une itérative.
- Utiliser des structures de données adaptées (liste, pile, ensemble).
- Comparer les deux approches en termes de fonctionnement et limitations.
Outils utilisés
- Java - langage principal
- Jsoup - bibliothèque pour parser le HTML
- IntelliJ IDEA Community Edition - IDE
Analyse méthodique du problème
J’ai commencé par analyser le problème en plusieurs étapes : récupérer le contenu HTML d’une page, extraire tous les liens internes, puis visiter ces liens sans jamais revisiter une page déjà visitée. Ce processus devait être répété jusqu’à ce que toutes les pages du site soient explorées.
Pour cela, j’ai identifié les structures nécessaires : une liste ou pile pour stocker les pages à visiter, et un ensemble pour garder la trace des pages déjà explorées.
Extraits de code : versions récursive et itérative
Voici des extraits simplifiés montrant les deux approches que j’ai développées pour parcourir les pages web. Chaque version résout le même problème, mais avec une logique différente.
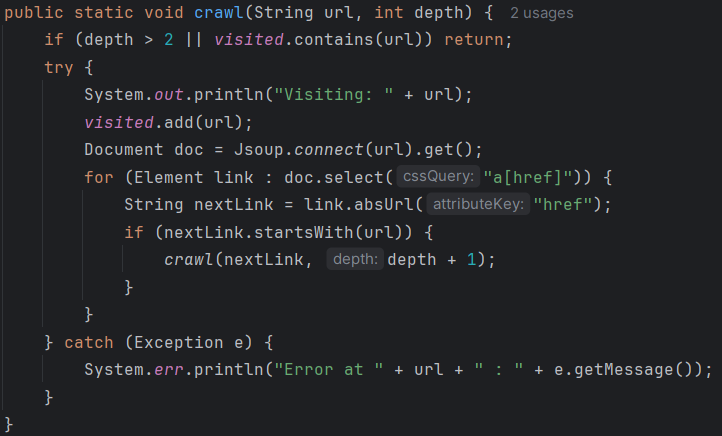
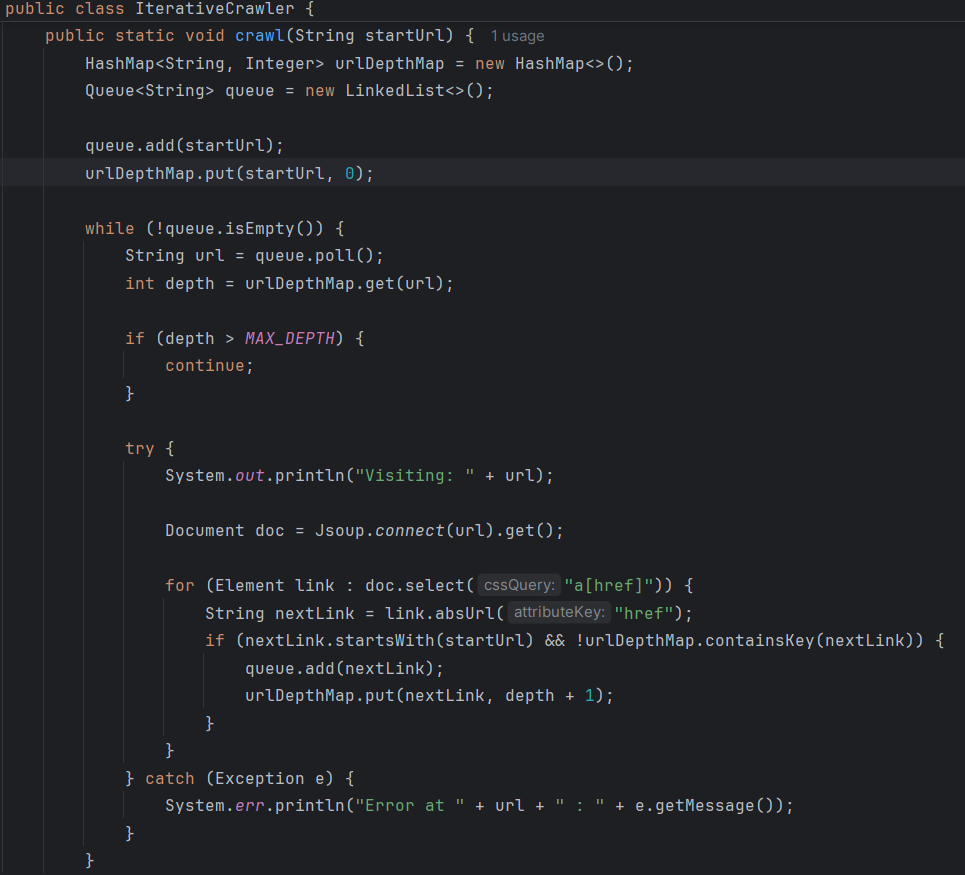
Les deux versions utilisent Jsoup pour récupérer les liens HTML, mais la version itérative est plus stable à grande échelle, car elle évite les erreurs de dépassement de pile causées par la récursivité.
Raisonnement algorithmique et structures de données
Ce projet m’a permis de comprendre et d’appliquer des notions fondamentales en algorithmique, comme le parcours en profondeur (DFS), l’utilisation d’ensembles pour éviter les doublons, et la gestion de la pile d’appels ou pile explicite. J’ai aussi réfléchi aux conditions d’arrêt pour éviter les boucles infinies.
Validation et justification des choix
J’ai testé les deux versions sur plusieurs sites web, en comparant les résultats et en mesurant la robustesse face à des sites complexes. La version itérative s’est révélée plus stable, justifiant mon choix final pour cette approche.
Bilan personnel
Ce projet m’a aidé à développer une pensée algorithmique plus rigoureuse, ainsi qu’à mieux comprendre les avantages et limites des méthodes récursives et itératives. J’ai également amélioré ma capacité à choisir les structures de données adaptées à un problème donné.
Points forts : analyse claire du problème, double implémentation, compréhension des structures.
Difficultés : gestion des limites de récursion, optimisation des performances.
Axes d’amélioration : gestion des erreurs réseau, optimisation mémoire, interface utilisateur.