Comparaison d'approches algorithmiques : Tris de base
Explication de la SAE
Cette SAE a pour but de découvrir et d’implémenter trois algorithmes de tri fondamentaux en informatique : le tri par sélection, le tri à bulle, et le tri par insertion. L’objectif est de comprendre leurs fonctionnements, de les coder en Java, puis de comparer leurs performances dans différents cas d’utilisation.
Objectifs
- Comprendre les principes des tris par sélection, bulle et insertion.
- Implémenter ces algorithmes dans une classe Java nommée
TriUtil. - Mettre en place un protocole de test pour valider la correction des tris.
- Comparer les performances (temps d’exécution) des différents tris sur plusieurs jeux de données.
Outils utilisés
- Java pour l’implémentation des algorithmes.
- Environnement de développement (IDE) comme Eclipse, IntelliJ ou VSCode.
- Outils de mesure de performance (ex: System.nanoTime() en Java).
Le tri à bulle
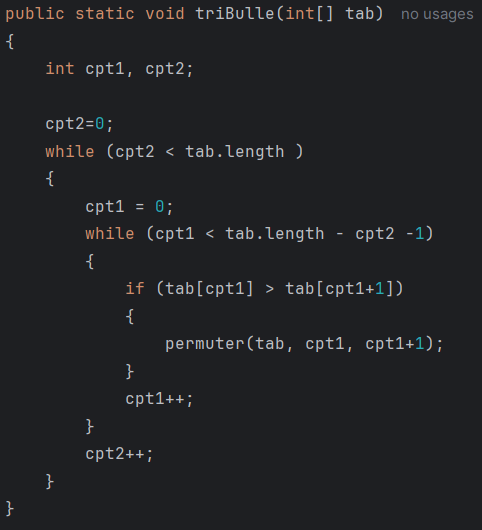
Le tri à bulle fonctionne en parcourant plusieurs fois le tableau à trier et en échangeant les éléments adjacents qui sont dans le mauvais ordre. C’est un algorithme simple à comprendre mais peu efficace pour les grands tableaux car sa complexité est en O(n²).
Le tri par sélection
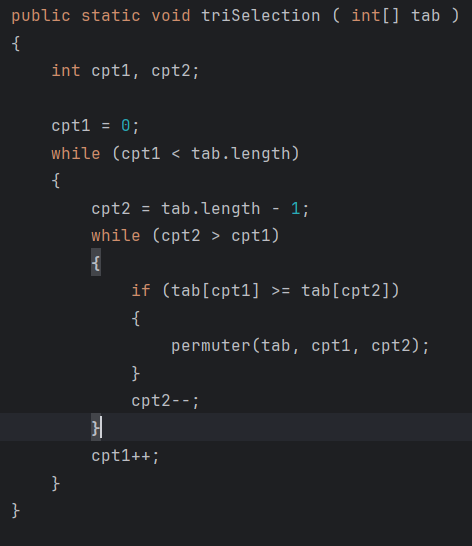
Le tri par sélection consiste à chercher à chaque étape l’élément minimum du tableau non trié et à l’échanger avec la première position non triée. Il effectue donc un nombre fixe de comparaisons mais peu d’échanges. Sa complexité est également O(n²).
Le tri par insertion
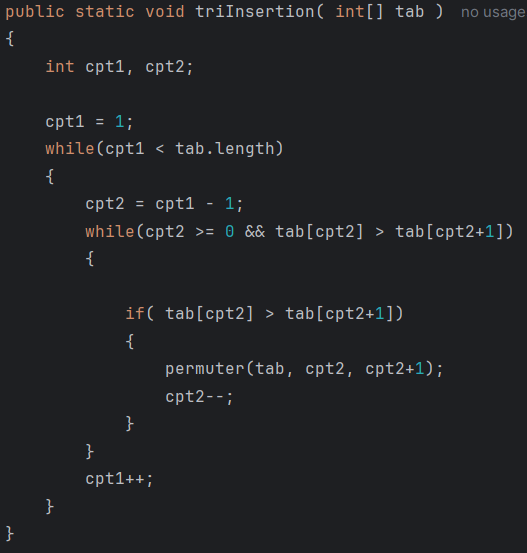
Le tri par insertion construit progressivement un sous-tableau trié, en insérant chaque nouvel élément à la bonne position. Il est souvent plus performant que les deux autres sur des tableaux déjà partiellement triés. Sa complexité moyenne reste O(n²), mais dans le meilleur cas elle est O(n).